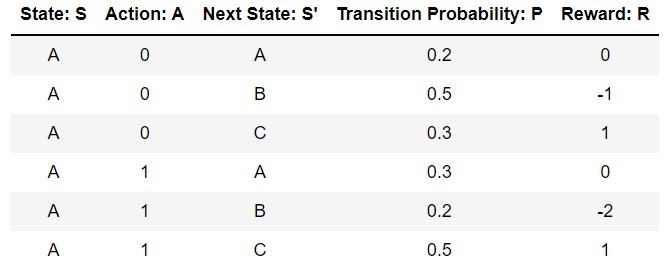
You say that action “0” is for left/right and action “1” is for up/down.
In the table below, you enable to go to case C by doing a “0” which is impossible… Why so do you take this into account ??
Is it not better to give a transition probability equal to 0 for this case ??
Another question : as B is a trap, why the probabilities of going to A or C from B are not equal to 0 (and 1 for going B to B)? Same thing for C : as C is a target, why the probabilities for going from C to A or B are not equal to 0 (and make C to C = 100%) ?
In the table below, you enable to go to case C by doing a “0” which is impossible… Why so do you take this into account ??
Well this is allowed in order to make a little more interesting the example. This is modelling that something may go wrong and even if you take a ‘0’ action, you may end reaching ‘C’ state, as it happens in real life. If we are modeling a very mechanical world where everything work perfect, the table should have transition probabilities of 0 to all combinations except for A - 0 - B and A - 1 - C which would have 1. But that is never the case is real life and very simple example for the teaching.
as B is a trap, why the probabilities of going to A or C from B are not equal to 0 (and 1 for going B to B)?
Because the transition probabilities have nothing to do with the task at hands. Independently of the task you want the robot to perform (in this case, the task is going to C while avoiding B), there are probabilities of changing between states which model the world in which the robot will have to perform its task.
You are confusing the result you want for the problem with how the robot world works.
I think that I answered your questions but let me know if still not clear. I’ll be happy to clarify any doubt.
So during the training all actions can be taken but the reward given for specifics ones will tend to construct the greedy policy to be a policy where these actions will never be taken in reality ?
But what I don’t understand is why you are not doing this in the “train_drone.py” program:
def get_env_feedback(S, A):
# This is how agent will interact with the environment
if A == 'fly_right':
if S == N_STATES - 2:
S_ = 'goal'
R = 1
else:
S_ = S + 1
R = 0
if A == 'fly_left':
R = 0
if S == 0:
S_ = S
else:
S_ = S - 1
return S_, R
Here, there 100% of chance that the drone take the correct action…
For example, here, the drone have 100% chance to go to state 3 when in state 2 by taking action right and 0% of chance to go to wrong state (state 1 by taking action right)