hi,
ive made a ros2 workspace and package but i have some pre written code done up in python for these luxonis cameras . i tried moving them into the package and rebuilding the package but when i tried to run the package then it gave me errors. any help to fix this issue would be much appreciated or even a direction which i can look into .
many thanks,
Kieran
@kierankirby123
You need to give more details that this so people can know exactly how to help.
- Show the error message with screenshots.
- State the ROS version you are using.
- Try to create a rosject of this package on this platform and share a link to it.
- etc
the error is that no module name depthai
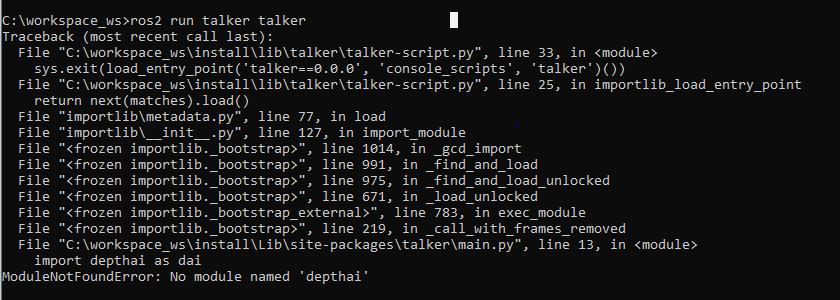
. i have managed to make a package and workspace successfully
also attached is the code i am trying to implement for this.
#!/usr/bin/env python3
#This is the current design that we have, its capable of running multiple cameras at the same time with moblenet object detector
#It’s currently set to only detect people, the output is a live video from the camera with the objects that are detected along with information
#on each object (the ID number, device that detected it, spatial coordinates and FPS from the camera)
#Imports
import rclpy
from rclpy.node import Node
from std_msgs.msg import String
from pathlib import Path
import cv2
import sys
import depthai as dai
import contextlib
import blobconverter
import time
import json
import argparse
import numpy as np
from time import monotonic
from imutils.video import VideoStream
from depthai_sdk import PipelineManager, NNetManager, PreviewManager, Previews, FPSHandler
#import rcply
class TalkerNode(Node):
def __init__(self):
super().__init__('talker')
self.publisher = self.create_publisher(
String,
'talker',
10
)
timer_period = 0.5
self.timer = self.create_timer(
timer_period,self.timer_callback
)
def timer_callback(self):
msg = String()
msg.data = 'Hello!'
self.publisher.publish(msg)
def main(args = None):
rclpy.init(args=args)
talker_node = TalkerNode()
rclpy.spin(talker_node)
rclpy.shutdown()
Labels for objects in the label map
labelMap = [“background”, “aeroplane”, “bicycle”, “bird”, “boat”, “bottle”, “bus”, “car”, “cat”, “chair”, “cow”,
“diningtable”, “dog”, “horse”, “motorbike”, “person”, “pottedplant”, “sheep”, “sofa”, “train”, “tvmonitor”]
Path to the model compiled with 6 shaves
nnPathDefault = str((Path(file).parent / Path(‘models/mobilenet-ssd_openvino_2021.4_5shave.blob’)).resolve().absolute())
parser = argparse.ArgumentParser()
parser.add_argument(‘nnPath’, nargs=’?’,
help=“Path to mobilenet detection network blob”, default=nnPathDefault)
parser.add_argument(’-ff’, ‘–full_frame’, action=“store_true”,
help=“Perform tracking on full RGB frame”, default=False)
args = parser.parse_args()
fullFrameTracking = args.full_frame
syncNN = True
This can be customized to pass multiple parameters
def getPipeline():
# Start defining a pipeline
pipeline = dai.Pipeline()
# Define a source - color camera
cam_rgb = pipeline.create(dai.node.ColorCamera)
# Define Network
spatialDetectionNetwork = pipeline.create(dai.node.MobileNetSpatialDetectionNetwork)
# Define Mono cameras
monoLeft = pipeline.create(dai.node.MonoCamera)
monoRight = pipeline.create(dai.node.MonoCamera)
stereo = pipeline.create(dai.node.StereoDepth)
# Define Object Tracker
objectTracker = pipeline.create(dai.node.ObjectTracker)
# Create output
xout_rgb = pipeline.create(dai.node.XLinkOut)
xout_nn = pipeline.create(dai.node.XLinkOut)
xoutBoundingBoxDepthMapping = pipeline.create(dai.node.XLinkOut)
xoutDepth = pipeline.create(dai.node.XLinkOut)
# Create output for Object Tracker
trackerOut = pipeline.create(dai.node.XLinkOut)
# Set the names for the output stream
xout_rgb.setStreamName("rgb")
xout_nn.setStreamName("detections")
xoutBoundingBoxDepthMapping.setStreamName("boundingBoxDepthMapping")
xoutDepth.setStreamName("depth")
# Set stream name for Object Tracker
trackerOut.setStreamName("tracklets")
# Properties
cam_rgb.setPreviewSize(300, 300)
cam_rgb.setBoardSocket(dai.CameraBoardSocket.RGB)
cam_rgb.setResolution(dai.ColorCameraProperties.SensorResolution.THE_1080_P)
cam_rgb.setInterleaved(False)
# Properties for the left and right mono cameras
monoLeft.setResolution(dai.MonoCameraProperties.SensorResolution.THE_400_P)
monoLeft.setBoardSocket(dai.CameraBoardSocket.LEFT)
monoRight.setResolution(dai.MonoCameraProperties.SensorResolution.THE_400_P)
monoRight.setBoardSocket(dai.CameraBoardSocket.RIGHT)
# Setting Node Configs
stereo.setDefaultProfilePreset(dai.node.StereoDepth.PresetMode.HIGH_DENSITY)
stereo.setDepthAlign(dai.CameraBoardSocket.RGB)
stereo.setOutputSize(monoLeft.getResolutionWidth(), monoLeft.getResolutionHeight())
spatialDetectionNetwork.setBlobPath(args.nnPath)
spatialDetectionNetwork.setConfidenceThreshold(0.6) # Confidence level for a detection, less that 60% sure ignore, can be changed if desired
spatialDetectionNetwork.input.setBlocking(False)
spatialDetectionNetwork.setBoundingBoxScaleFactor(0.5)
spatialDetectionNetwork.setDepthLowerThreshold(100)# Set min distance
spatialDetectionNetwork.setDepthUpperThreshold(30000)# Set the max distance
objectTracker.setDetectionLabelsToTrack([15]) # track only person can add more tracking class options for the network e.g for bottle and person ([5,15])
# possible tracking types: ZERO_TERM_COLOR_HISTOGRAM, ZERO_TERM_IMAGELESS, SHORT_TERM_IMAGELESS, SHORT_TERM_KCF
objectTracker.setTrackerType(dai.TrackerType.ZERO_TERM_COLOR_HISTOGRAM)
# take the smallest ID when new object is tracked, possible options: SMALLEST_ID, UNIQUE_ID
objectTracker.setTrackerIdAssignmentPolicy(dai.TrackerIdAssignmentPolicy.SMALLEST_ID)
# Linking
monoLeft.out.link(stereo.left)
monoRight.out.link(stereo.right)
cam_rgb.preview.link(spatialDetectionNetwork.input)
objectTracker.passthroughTrackerFrame.link(xout_rgb.input)
objectTracker.out.link(trackerOut.input)
if fullFrameTracking:
cam_rgb.setPreviewKeepAspectRatio(False)
cam_rgb.video.link(objectTracker.inputTrackerFrame)
objectTracker.inputTrackerFrame.setBlocking(False)
# do not block the pipeline if it's too slow on full frame
objectTracker.inputTrackerFrame.setQueueSize(2)
else:
spatialDetectionNetwork.passthrough.link(objectTracker.inputTrackerFrame)
spatialDetectionNetwork.passthrough.link(objectTracker.inputDetectionFrame)
spatialDetectionNetwork.out.link(objectTracker.inputDetections)
stereo.depth.link(spatialDetectionNetwork.inputDepth)
return pipeline
contextlib — Utilities for with-statement contexts — Python 3.10.5 documentation
with contextlib.ExitStack() as stack:
device_infos = dai.Device.getAllAvailableDevices()
# Check for number of avaliable devices connected
if len(device_infos) == 0:
raise RuntimeError(“No devices found!”)
else:
print(“Found”, len(device_infos), “devices”) # Display device name
devices = {}
for device_info in device_infos:
# Note: the pipeline isn't set here, as we don't know yet what device it is.
# The extra arguments passed are required by the existing overload variants
openvino_version = dai.OpenVINO.Version.VERSION_2021_4
usb2_mode = False
device = stack.enter_context(dai.Device(openvino_version, device_info, usb2_mode))
# Note: currently on POE, DeviceInfo.getMxId() and Device.getMxId() are different!
print("=== Connected to " + device_info.getMxId()) # Display what device has been connected to
mxid = device.getMxId()
cameras = device.getConnectedCameras()
usb_speed = device.getUsbSpeed()
# Get a customized pipeline based on identified device type
pipeline = getPipeline()
device.startPipeline(pipeline)
# Output queue will be used to get the rgb frames from the output defined above
devices[mxid] = {
'rgb': device.getOutputQueue(name="rgb"),
'nn': device.getOutputQueue(name="detections"),
'boundingBoxDepthMapping' : device.getOutputQueue(name="boundingBoxDepthMapping"),
'depth' : device.getOutputQueue(name="depth"),
'tracklets' : device.getOutputQueue(name="tracklets"),
}
startTime = time.monotonic()
counter = 0
frame = 0
fps = 0
count = 0
coords_prev = 0
while True:
# Iterate through all connected devices
for mxid, q in devices.items():
frame = q['rgb'].get().getCvFrame()
tracklets = q['tracklets'].get()
counter+=1
current_time = time.monotonic()
# Counter to find the FPS of the output video
if (current_time - startTime) > 1 :
fps = counter / (current_time - startTime)
counter = 0
startTime = current_time
trackletsData = tracklets.tracklets
# Hold the values of the spatial coordinates and the Object ID number
x = 0
y = 0
z = 0
ID_num = 0
# Iterate over the detected object data and extract desired info
for detection in trackletsData:
# Denormalize Bounding Box
roi = detection.roi.denormalize(frame.shape[1], frame.shape[0])
x1 = int(roi.topLeft().x)
y1 = int(roi.topLeft().y)
x2 = int(roi.bottomRight().x)
y2 = int(roi.bottomRight().y)
# Get the label ID
try:
label = labelMap[detection.label]
except:
label = detection.label
cv2.putText(frame, str(label), (x1+10, y1+20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, 255)
#cv2.putText(frame, "{:.2f}".format(detection.confidence*100), (x1+10, y1+35), cv2.FONT_HERSHEY_SIMPLEX, 0.5, 255)
cv2.putText(frame, f"ID: {[detection.id]}", (x1 + 10, y1 + 35), cv2.FONT_HERSHEY_TRIPLEX, 0.5, (140, 250, 15))
# Extract the spatial coords of the tracked object
cv2.putText(frame, f"X: {int(detection.spatialCoordinates.x)}mm", (x1+10, y1+50), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (48,213,200))
cv2.putText(frame, f"Y: {int(detection.spatialCoordinates.y)}mm", (x1+10, y1+65), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (48,213,200))
cv2.putText(frame, f"Z: {int(detection.spatialCoordinates.z)}mm", (x1+10, y1+80), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (48,213,200))
# Put Bounding Box around the tracked object
cv2.rectangle(frame, (x1,y1),(x2,y2),(255,0,0), cv2.FONT_HERSHEY_SIMPLEX)
# Save the spatial coordinates of the bounding box of the detected object (X,Y,Z)
x = int(detection.spatialCoordinates.x)
y = int(detection.spatialCoordinates.y)
z = int(detection.spatialCoordinates.z)
coordinates = " X " + str(x) + " Y " + str(y) + " Z " + str(z) + "\n"
# Save the ID number for the detected object
ID_num = detection.id
# Create a text file to save the spatial coordinates of each tracked object at every frame from all cameras
# w - overwrite what's in text file, a - append/add to the text file, r - read the text file
#outfile = open('coords.txt', 'w')
## Save the Device ID, object type, ID number of object and the coordinates to a text file
#outfile.write("Device ID: " + mxid + " ID Number: " + str(ID_num) + " Object: " + str(label) + coordinates)
#outfile.close()
# outfile = open('coords.txt', 'r')
# #outfile.write("Device ID: " + mxid + " Object: " + str(label) + " ID Number: " + str(ID_num) + coordinates)
# lines = outfile.readlines()
# outfile = open('coords.txt', 'a')
# for i in lines:
# if (i[0:43] == "Device ID: 184430102111F90F00 ID Number: 0" + str(coords_prev)):
# outfile.replace(i,"Device ID: " + mxid + " ID Number: " + str(ID_num) + " Object: " + str(label) + coordinates)
# #print(coordinates)
# else:
# #open(outfile,'a')
# outfile.write("Device ID: " + mxid + " ID Number: " + str(ID_num) + " Object: " + str(label) + coordinates)
# #print(coordinates)
# # 0 - 42
# coords_prev = coordinates
# outfile.close()
#print("Device ID: " + mxid + " Object: " + str(label) + " ID Number: " + str(ID_num) + " X " + str(x) + " Y " + str(y) + " Z " + str(z) + "\n")
#outfile = outfile.replace(mxid, mxid)
#if (mxid[detection] == mxid[detection-1] & str(ID_num[detection]) == str(ID_num[detection])):
# outfile.replace(str(x), str(x))
# Show the frame and FPS
cv2.putText(frame, "NN fps: {:.2f}".format(fps), (2, frame.shape[0] - 4), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,255,0)) #Display FPS when there is an object detected
cv2.imshow(f"rgb - {mxid}", frame)
if cv2.waitKey(1) == ord('q'): # Press q key to stop
breakfrom the error message, you can try installing the missing package in your virtual environment (if any, but recommended):
pip3 install depthai
This topic was automatically closed 10 days after the last reply. New replies are no longer allowed.