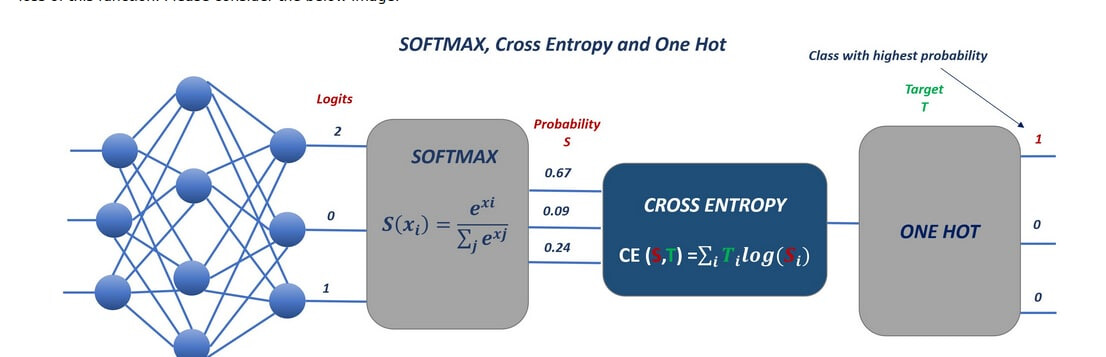
I think understand the points of cross entropy and one hot. But why are they in series?
In my brain, cross entropy is a measure of how well/bad the model performs on the given input (same as MSE but for classification purposes). And one hot is simply a way to make a choice based on certainty. One thing is for training and the other for output (respectively). So why aren’t they in parallel both using the output from the softmax function? Why does One-hot use the output from cross entropy instead of the softmax output?
Hello @GasPatxo ,
Images included in the course can be somehow misleading however the theory discussed is correct. The softmax function estimates the output from the neural network and computes probabilities of the input (to neural network) belonging to a certain class
In order to measure how the backpropagation performs we compare simply two vectors. The natural way to measure the distance between those two probability vectors (softmax and one-hot) is called the Cross Entropy.
As it was discussed, one vector that comes out of your classifiers and contains the probabilities of your classes (softmax) and the one-hot encoded vector that corresponds to your labels (length of vector depends on the number of classes; each vector has only one “1” representing Hot, rest is null).
This topic was automatically closed after 3 days. New replies are no longer allowed.